MLLMs Know Where to Look:
Training-Free Perception of Small Visual Details with Multimodal LLMs
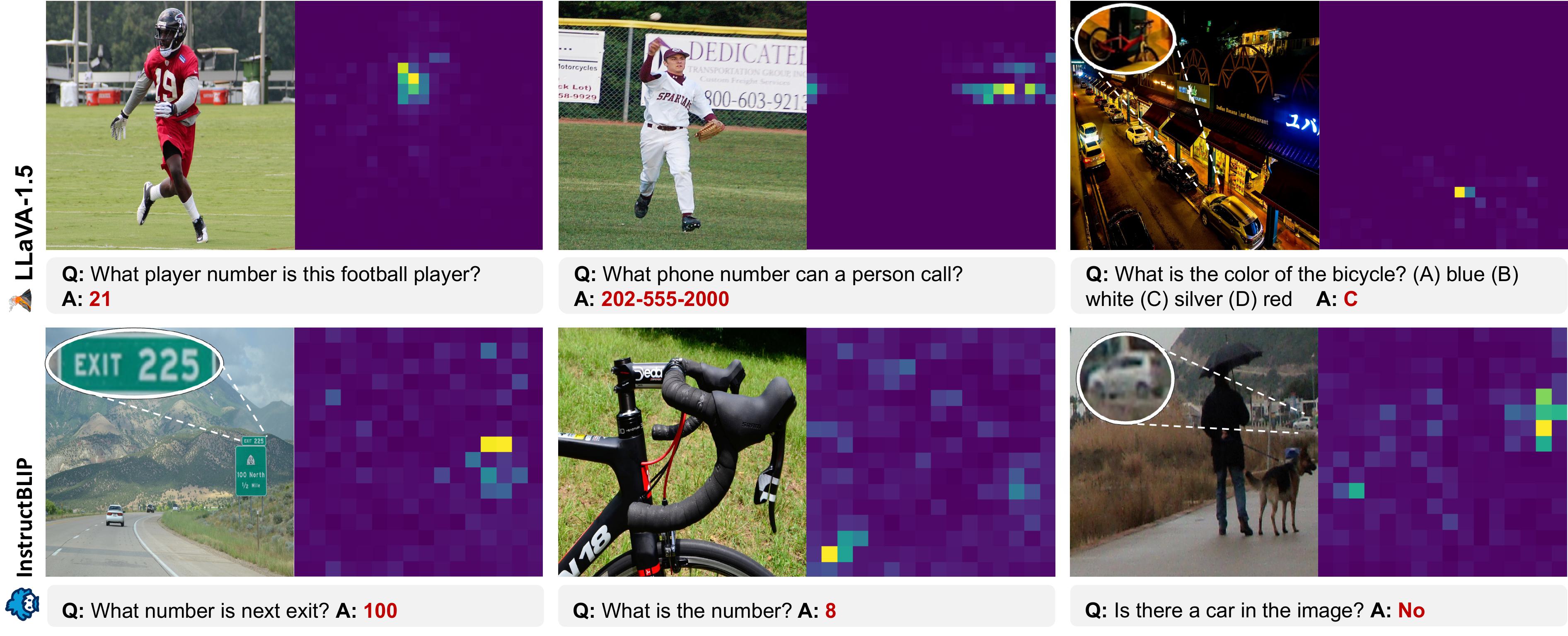
Examples of MLLMs knowing where to look despite answering incorrectly. The right panel in each example displays relative attention to image of one layer in the MLLM.
Abstract
Multimodal Large Language Models (MLLMs) have experience rapid progress in recent years. Given their potential integration into many critical applications, it is important to understand the limitations of their perception ability. In this work, we study whether MLLMs can perceive small detailed visual information as well as large ones in images. In particular, we observe that their accuracy in answering visual questions is very sensitive to the size of the visual subject of the question. We further show that this effect is causal by observing that human visual cropping can significantly mitigate this sensitivity. Next, we study the attention patterns of MLLMs when answering visual questions, and intriguingly find that they consistently know where to look, even when they provide the wrong answer. Based on these findings, we then construct automatic visual cropping methods that leverage the internal knowledge of any MLLM itself, in the form of attention and gradient maps, to help it better perceive the small visual subject of any question. We study our proposed methods on two popular MLLMs and seven multimodal benchmarks, and show that they can significantly improve MLLMs' accuracy without requiring any training. Our findings suggest that MLLMs should be used with caution in detail-sensitive applications, and that visual cropping with model's own knowledge is a promising direction to improve their performance.
Automatic Visual Cropping
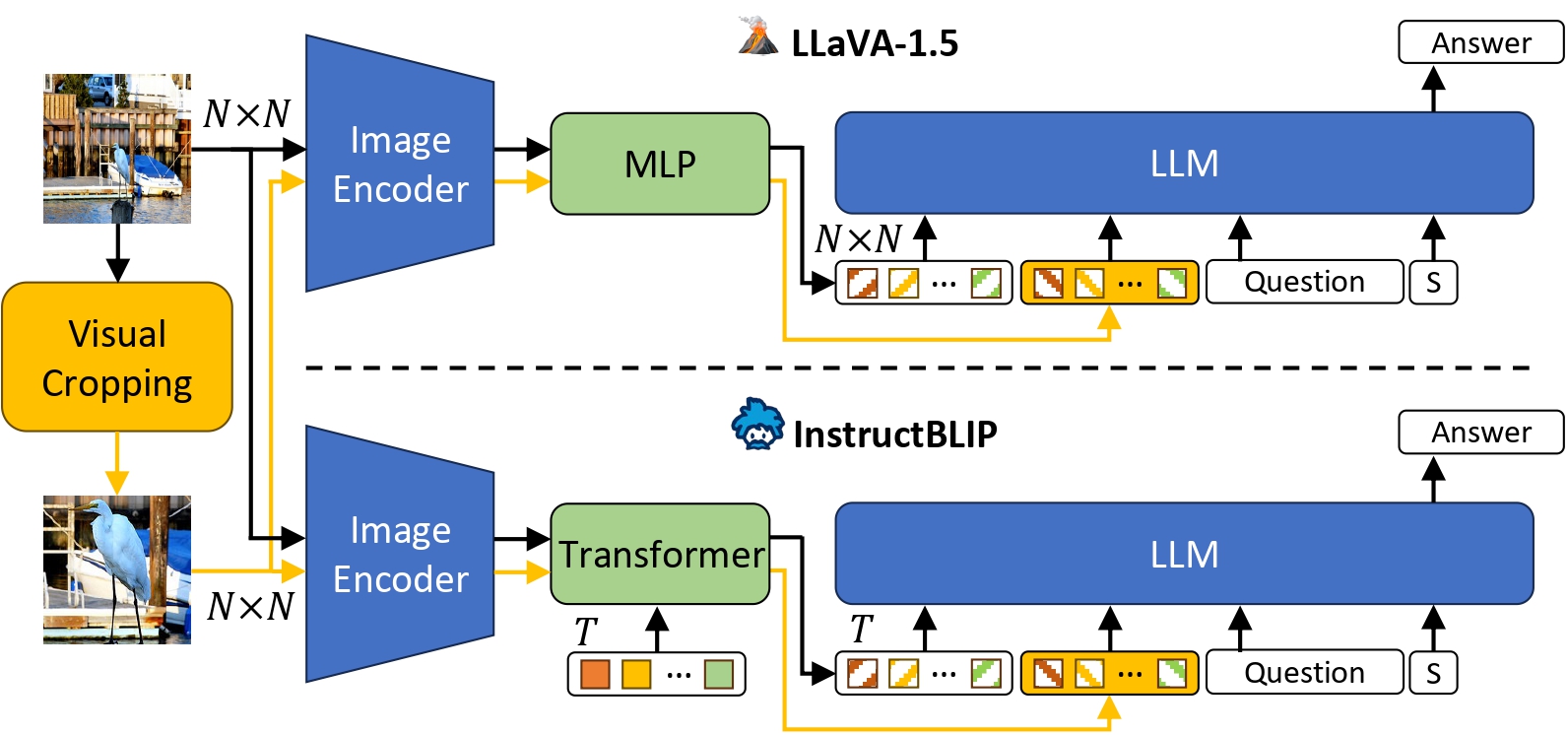
Illustration of the proposed visual cropping approach applied to two MLLMs.
Visual Cropping Methods Analysis

Examples of rel-att helping MLLMs correct their mistakes (cyan-colored bounding box shows cropped region by rel-att; zoom-in insets are displayed for better readability).
| Model | Smaller Visual Concepts | Larger Visual Concepts | ||||||
|---|---|---|---|---|---|---|---|---|
| TextVQA† | V* | POPE | DocVQA | AOKVQA | GQA | VQAv2 | ||
| LLAVA-1.5 | no cropping | 47.80 | 42.41 | 85.27 | 15.97 | 59.01 | 60.48 | 75.57 |
| rel-att | 55.17 | 62.30 | 87.25 | 19.63 | 60.66 | 60.97 | 76.51 | |
| grad-att | 56.06 | 57.07 | 87.03 | 19.84 | 59.94 | 60.98 | 76.06 | |
| pure-grad | 51.67 | 46.07 | 86.06 | 17.70 | 59.92 | 60.54 | 75.94 | |
| InstructBLIP | no cropping | 33.48 | 35.60 | 84.89 | 9.20 | 60.06 | 49.41 | 76.25 |
| rel-att | 45.44 | 42.41 | 86.64 | 9.95 | 61.28 | 49.75 | 76.84 | |
| grad-att | 45.71 | 37.70 | 86.99 | 10.81 | 61.77 | 50.33 | 76.08 | |
| pure-grad | 42.23 | 37.17 | 86.84 | 8.99 | 61.60 | 50.08 | 76.71 | |
BibTeX
@article{park2021nerfies,
author = {Park, Keunhong and Sinha, Utkarsh and Barron, Jonathan T. and Bouaziz, Sofien and Goldman, Dan B and Seitz, Steven M. and Martin-Brualla, Ricardo},
title = {Nerfies: Deformable Neural Radiance Fields},
journal = {ICCV},
year = {2021},
}